We’ve been on a rough ride lately with an update of our suggestion engine that didn’t go as planned. We’ve had a chance to discuss with some of you who reached out through our support system and we immediately communicated with in-product messages and by updating our knowledge base but I wanted to explain what’s been going on to all of you – whether or not you’ve been impacted.
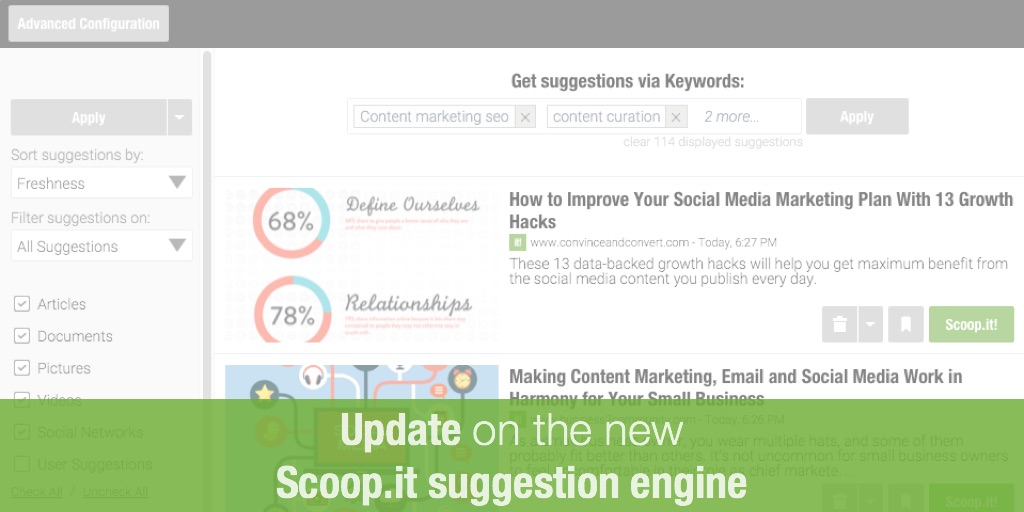
What the Scoop.it suggestion engine is
The Scoop.it suggestion engine is a key component of our platform and value proposition: it’s the piece of technology that crawls the web for you, to fetch content that’s relevant to your audience and that you might want to curate and share. It’s sophisticated technology: with now millions of users to serve who each have multiple keywords (sometimes dozens), it scans tens of millions of webpages all across the web, analyzes them for matching content and ranks them according to various criteria (social signals, keyword density, data from our user base, etc…). And it also obviously needs to go fast so you can get fresh relevant content as soon as you connect.
How the Scoop.it suggestion engine discovers content to curate
To build this technology, we were historically dependent on other platforms’ APIs (for those of you who are not technical, an API is an interface that enables one software application to work with another one). When we started the beta version of Scoop.it years ago, in a typical startup way, we wanted to prove the validity of the concept as fast as we could. So we leveraged existing open APIs from Twitter, Google, YouTube and other content platforms to build the very first version of that suggestion engine. Over time we made a lot of improvements to this technology and reduced the dependency to these APIs as we felt we could develop a better way to find content and content sources as well as rank them by quality: by using signals from our millions of users and visitors, we’re in a unique position to enrich content sources naturally with what people curate and to learn what constitutes good ranking criteria as they either accept or reject suggestions. But there’s another reason we wanted to reduce our dependency to third-party APIs: to be able to offer a sustainable service independently of changes made by other platforms.
And this is where sh**t happened recently.
The new Scoop.it suggestion engine
Over the past few months, our engineering team had been working on a new major release of our suggestion engine. This new version had several objectives, among which:
- Be more performant by leveraging our own “corpus”: instead of waiting for new content to be raising above the noise through one of the APIs we’ve been using, we can proactively crawl all the sources that are in our own index, i.e. sources that at least one Scoop.it user has already curated. This index keeps increasing with the best sources as you guys do an awesome job not just curating from suggestions but also scooping content on the fly with our bookmarklet or Chrome extension. And that’s not all, we have great data on this content that we can use to optimise the way we rank it.
- Be completely independent from third-party APIs for the same reasons (we had reduced our dependency so far but were still not 100% independent).
This new version is the results of a lot of work that started a long time ago: R&D work, experimentations, development, coding and a lot of tests.
About 10 days ago, we felt we were almost there – maybe 99% there.
But about 10 days ago, something else happened: Google shut down one of the APIs we had been using in our suggestion engine – that is in the version of the suggestion engine you all had been using so far.
Coincidence but… bad coincidence.
We looked at our options and figured our chances to have Google extend API access for us would be very slim. So we decided to release the new version into production.
From a technical point of view, this was a success: the new suggestion engine seems to be stable and run pretty well (with one notable exception on performance – see below). But this new release also changes the experience for using the suggestion engine and caused confusion for some of you.
Maybe you’ve been reading all of this and are thinking “what the hell is he talking about?” because you haven’t seen any issues. Luckily, a lot of you are in that case and have seen only improvements in the quality of the suggested content. But for some of you, the new suggestion engine messed with your content curation work in a way we didn’t anticipate. I’m really sorry for these issues and the frustration they generated. We’ve been busy bringing some corrections so let’s recap point by point what these issues were and where we are now.
New UX:
For some roadmap and versioning reasons, the new suggestion engine only runs with a slightly new UX for the suggestion panel that essentially displays filters in the left column and other minor changes (such as the way to clear your suggestion queue – see also below on this). This new UX has gone through more than testing: it’s been pretty much the UX we’ve used for Scoop.it Content Director that launched at the beginning of the year. Since we were happy with the results, we built the new suggestion engine for the entire platform on this so the new UX came as a surprise to you and we didn’t do a good job at warning you about this change (nor had much chance to, to be honest…) as we normally like to.
Slow loading time (fixed):
Because this new suggestion engine works entirely on our own index of content, it’s supposed to be much faster. It now is but for some time, some of you saw this:
Obviously not what we wanted… but again fixed by now.
Relevance vs Freshness (fixed):
The filter to use relevance vs freshness brings much more contrasted results with this new version. In addition, our new crawler is very agressive at getting content (it never stops trying to get some). Some of you who were in the relevance mode ended up seeing very old posts in their suggestions for that reason. That’s not necessarily bad: with the new suggestion engine, you’ll be able to unearth old gems that are very relevant which wasn’t possible in the past. But the previous version, even in relevance priority mode, kept bringing relatively fresh content. So the experience was totally different and confusing to some of you – again not all as that depends on your keywords and priority mode.

As a resolution, we brought everybody back to Freshness priority mode and we encourage you to activate the Relevance priority mode in conjunction with the date filter if you want relevant content that’s not older than X days/month.

Check sections 3 and 8 of this knowledge base article to et details on how to do that.
Infinite amount of suggested content (fixable… if you want to):
Our new engine is a lot more agressive than the previous one at searching content for you. We think that will end up being a good thing as it can help those of you with niche topics find a lot more content but for some of you, this came as a shock – particularly those of you who adopt a “zero-inbox” policy with content suggestions and clean their entire queue so that they know where they are and can rapidly identify new content to curate.

We’re not fixing that but you can use the above time filter to enjoy much more limited suggestions and target inbox zero. You can for instance filter out content older than 7 days and you’ll have much less content. Section 4 of that knowledge base article explains how to do that in greater details.
Suggestions keep coming back even though I clear them (fixed but read below)
This one’s pretty tricky… First, some of you were confused by the fact we replaced the trash icon by this:

The reason we did this is that a lot of users missed the previous icon. But again, we didn’t have much chance to give you a heads up or let you test drive this new UX which resulted in confusion.
Second, as we migrated to the new system, we had a bug that resulted in losing the list of content that had been previously discarded: so yes, it kept coming but this particular bug is now fixed.
But in addition to that, because the new engine is more agressive, it can give the perception that suggestions keep coming back: they don’t anymore. It’s just that there are now more of those to clean up before being at inbox zero. As with the previous version, cleaning your queue only cleans the suggestions currently being displayed. But if you have more than 100 suggestions for your content, new ones will pop up. In the past, the old engine brought fewer suggestions so you had less cleaning to do than now.
The solution? Same as above: apply a time limit filter if you want to get to inbox zero. Otherwise, don’t worry about it and let new suggestions replace the current ones the next time you connect. Stay in freshness mode and you’ll be always seeing fresh relevant content at the top.
“No exact match” issue, aka getting cubes for Cuba (fixed if you prioritize freshness, see below)
This one is also pretty tricky. When you search for something, you might type the word “running” and still be interested in content that mentions “runs” or “run”. To do that, search engines in general reduce words to their radical and consider that everything “run”, “runs” and “running” are all wanted in the query. That is unless you specify you’d like an exact match which can be done by adding brackets or quotes depending on the search engines. Historically, because our system is a suggestion engine and not a search engine – which means you can type multiple keywords – we’ve had better results using exact match by default so whenever you added “running”, we wouldn’t return content with simply “run” in there – or content about cubes when you wanted content on Cuba. The reason it worked better is that we offered the best of both worlds: we had a more specific query to run (for people only wanting “running” specifically) while at the same time, we could still please people who wanted both “running” and “run” by letting them add both keywords – something you can’t do in a search engine.
The migration broke that. And for a few days, all of our keywords were not running an exact match which meant some of you with keywords which radical is ambiguous (eg “Cuba” and “cubes” which both have “cub”) were getting what looked like spam in their suggestions.
This is now fixed but there’s a catch: we’ve had to reindex our content to get back to where we were which means new fresh content is ok but we’re still going back in time to re-index old content. What this means is that:
- If you prioritize freshness, you’re good.
- If you prioritize relevance, depending on how niche your keywords are, you might still be impacted and receive some old content not yet re-indexed that has nothing to do with what you wanted. The fix is then to add a time filter as mentioned above and as detailed in section 8 of this knowledge base article.
We’ve had more glitches than that: most of which are fixed (social signals that went missing were added back for instance), some of which we’re still working on. But these are the main causes of confusion we’ve seen.
We’re supposed to give you a great experience and make your life easier by saving you time and helping you reach your content goals. We clearly failed to do that for some of you these past 10 days. To offer you the best content software we can, we have to keep doing R&D and improving our software and technology. That means changing the way things are but it doesn’t mean confusing you without warning. So again, I apologize for the frustration you had and hope the above explanations will reassure you that we’re committed to build the best content platform there is. We’re confident that we made the right move and that the new suggestion engine will be even better than the previous one. But if you have any pending issues, don’t hesitate to reach out and our support team will be here to help.
Want to work smarter and start generating real results from your content marketing? Find out how to use the new Scoop.it Content Director to help you become a smarter marketer!


I understand the need to grow and improve but since the changes, the recommendations have become almost worthless to me. I curate articles for a client’s social media feeds and on a good day in the old system, I find enough to fill a few days worth of social media posts. Now, the feed is filled with cheap Amazon products and other advertising. The rare article that is appropriate is usually 6 moths old or more. I tried sorting by date as per above directions and it didn’t have any affect. I have to get this cleared up quick or… Read more »
Thanks for the feedback Jim. I just checked your suggestions and didn’t see any ads in the there. Have things gotten back to normal now? Remember you can also apply a date filter as mentioned in the post: you won’t get any old articles this way.
No. I’m afraid they haven’t gotten any better at all. If they aren’t ads, they are all links for food supplements and that sort of thing. I curate content for a client on urban nature, access to green space, place making, ecotherapy, the effect of time in nature on health. Up until the changes, the suggestions were good. Today for example, almost all of the suggestions are for food supplements and the like. Four of the first five recommendations today are for the same product on Ebay. The first suggestion is for an Etsy product. Any hope of getting back… Read more »
Hi Jim – Getting back to your support request of today. Thanks for the feedback.
Is there actually a way now to enforce exact match? I am tired of having matches for “product” when I have “productivity” set as a keyword.
Hi Fabrizio – You should be able to use ” ” to do exact match. Simply type in “productivity” instead of productivity.