
Everyday, there are 4 million blog posts, 100,000 news articles and 500,000 hours of video published on the Internet. A wealth of information and knowledge. A wealth of information and knowledge that is lost for most companies, at least for the most part.
Lost?
Step 1: content curation
Not entirely. Thanks to content curation technology, the Web can now be filtered. With content curation tools and platforms such as Scoop.it (among others of course), we can use more or less sophisticated ways to filter this huge amount of content that is published daily to zoom in on what matters to us. Good content curation technology is essential. It saves people a huge amount of time looking for content to share for marketing purposes or information that helps their organization make better decisions. And perhaps as importantly, without these filters, we would just be able to search – not discover. We would still find answers to what we don’t know but we wouldn’t know what we don’t know.
But until recently, all the solutions we’ve offered to deal with information overload – ours included – have revolved around the same basic idea: more – or more sophisticated – filters.

This means that so far, the act of analyzing and understanding content that was filtered by a content curation tool remained to be done entirely by its user.
And that part – analyzing and understanding content – is critical too.
When we look at what our most successful users do – whether they’re content marketers, market intelligence analysts, independent professionals or educators – they all share something. They don’t just filter information but they spend time analyzing it and understanding what it means. The practice of content curation helped them develop a deep understanding of their topics. They say the best writers are readers. We see that happening on the Scoop.it platform too.
Six years into the Scoop.it journey, I continue to talk to users and clients every day. It keeps me real and it helps me understand much better what they want. And what we’ve heard from hundreds of conversations is that there is a huge need to enable a greater understanding of what content is about and what it means:
- Content marketers want to understand what topics they should create content about and how to create the best content possible on these topics,
- They want to understand who has success on these topics – who’s influential – so they can find inspiration or potential co-marketing partners,
- Marketers in general want to understand whether their marketing actions have impact – in an absolute sense but also relatively to their competitors,
- Market analysts want to understand trending topics and how the conversations evolve on these topics so they can more easily understand what it means for their strategy.
In summary, we heard that beyond content curation, they needed insights and actionable data to make sense of web content.
What they needed was content intelligence.
Step 2: collecting data
So back in 2016, we decided to focus our R&D efforts on providing a solution to this problem. We felt we had a unique asset to do this: data.

Over time and as the platform became adopted by now more than 4 million users, we’ve collected a lot of data. In particular, we get a way to know when a new source is producing interesting content. Every time a Scoop.it user scoops an article using our browser extension on a new website, we have a chance to qualify this website and include it in the list of content sources we can monitor over time.
Having such a large volume of data is one of the key enablers or artificial intelligence algorithms. A lot of what AI does today is to recognize patterns. But to do so it needs to learn from a lot of examples. Very often, companies who’ve developed successful AI systems have done so because they have access to a lot of data.
By monitoring millions of web sources to filter them for content curation, we had a gold mine for an AI platform.
So we started to look at several ways to derive interesting insights from the data we had. Some failed, some were inconclusive and finally, we found a way to produce relevant and consistent results around topic identification at scale.
Our platform learned how to determine what a piece of content was about and how similar it was to another piece.
Step 3: content intelligence

Grouping a large volume of content into coherent topics was a major breakthrough. This enables us to do things such as:
- Finding what a website is about. For instance, your website or your competitors’ website.
- Finding out topics related to a certain keyword. For instance, we can find out what topics are covered by the 2,500+ articles published last month with a title that contains “content marketing”.
But we didn’t stop there.

We also enriched our data on content and its attributes with other metrics: performance metrics (such as shares on social networks) or quality metrics (such as word count or readability). And by adding these metrics into the engine, we can get even more interesting insights:
- Volume of content and popularity on various topics.
- Benchmarks between different websites across topics.
- Evolution of these metrics over time.
- etc…
From filtering the web to analyzing and understanding web content
So that’s where we are: last summer, we started testing internally a first prototype of the new technology we had developed. We showed results over the fall to some of our clients and we’re now running pilots to validate the value of our insights.
We decided to make this a new standalone product for now so we could iterate fast and validate the value proposition independently of the other benefits of the Scoop.it platform, in particular its content curation and publishing capabilities.
And we called it Hawkeye by Scoop.it.

Our goal with Hawkeye is to provide data and actionable insights that make content marketing more predictable. Nobody creates content in a vacuum: our content will always struggle for attention with many other pieces. The problem is that it’s really hard to look at what each competing website or influencer does on a number of topics – let alone measure it. There’s just too much to do. By leveraging artificial intelligence, Hawkeye monitors, analyzes and understands content from all over the web to help marketers create better content and measure its impact.
Here are some of the reports Hawkeye can already give:
Analyze a topic:
A list of topics related to a certain filter (eg: a keyword) together with volume count (how much content was published on that topic) and popularity (how many times they were shared). Here’s for instance a list of topics, Hawkeye found out all the posts mentioning “content marketing” in their titles, written in English and published over the last 30 days were about:
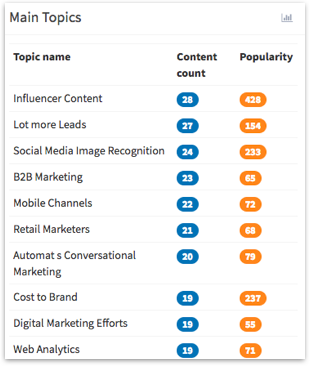
This can help with identifying topics more likely to be interesting for me as a content marketer (the low volume, high popularity ones since it means people are interested in them but they haven’t been too much covered yet). Or as a market analyst, I could use this to understand new trends I could decide to focus on.
Hawkeye brings data visualization so you can get a sense of the above data in a more visual way such as this graph:
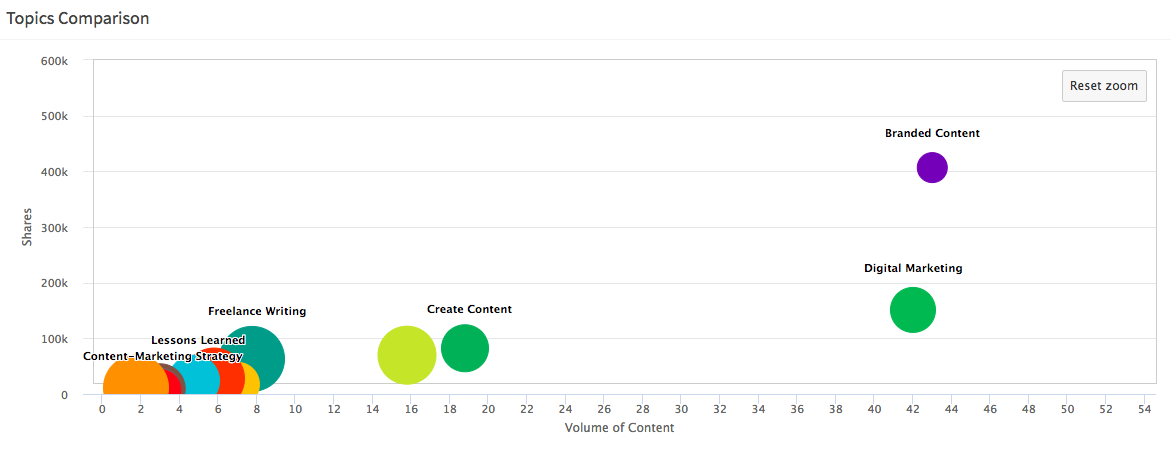
Analyze competitors content across topics
Instead of looking for all content related to say “content marketing”, one of the filters you can feed Hawkeye with is simply a list of websites. In particular a list of competitors or industry references. Hawkeye can come back with high-level KPI’s such as volume of content vs shares:
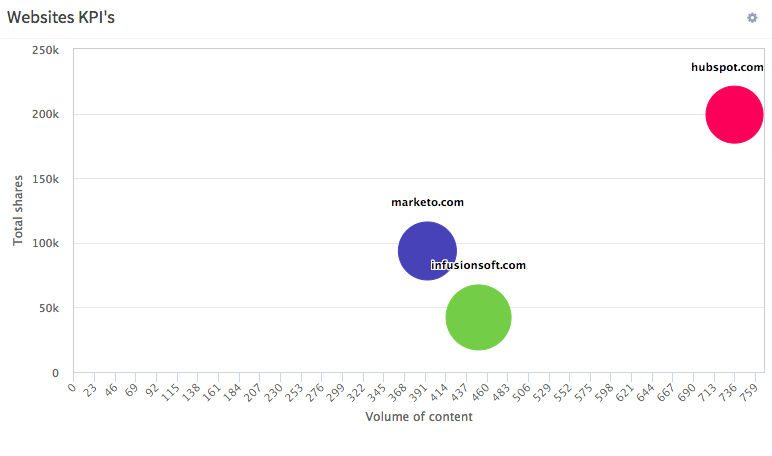
This can tell you whether you need to produce more content or better content (or both) to catch up with your competitors.
But Hawkeye can use topic analysis to go into greater details and analyze your content gap, ie what topics your competitors are focusing on vs what topics you’re focusing on:
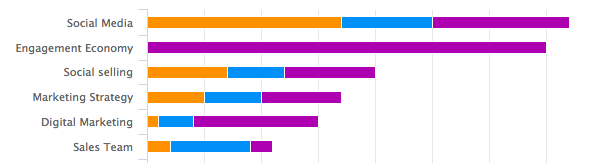
This is going to help you understand where to focus your efforts on, particularly what topics you should create content on.
You can also analyze the specific pieces of content on each of these topics and for instance get the most shared content on that topic as well as the quality score of each of these pieces of content:
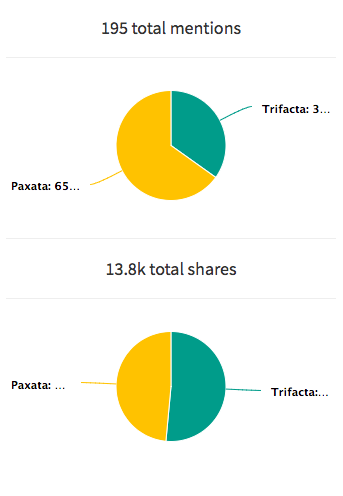
Measure share of voice and impact of earned media across topics
Content that helps your brand is not just the one you produce: it’s also what people say about your brand. Hawkeye can not only monitor your brand mentions in web content but also do that across topics and measure the impact of these mentions.
Hawkeye is still a very early product. We started our first pilots back in the summer and we’ve had amazing feedback so far. But it’s just the beginning. We’re working hard to develop it in many different ways. By enriching the type of data we’re using in our various reports. By creating new reports and data visualizations. By working on making our AI capable of understanding more and more things about content. Ultimately, we’d want Hawkeye to understand content like a human being would.
Because we want to be able to validate the value Hawkeye delivers and iterate fast based on feedback, we’ll continue to offer to run pilots to selected clients who can have significant return from content intelligence. If this describes you, we’d love to hear about it here and have a discussion.
We’ve had an amazing adventure with Scoop.it so far. From an idea we discovered in Silicon Valley to relocating to San Francisco to a platform with 4 million users and hundreds of B2B clients, it’s been quite a ride. But our mission is far from over. The new challenges and technology around content intelligence show us the next stage in our journey might be even more exciting.

 (4 votes, average: 5.00 out of 5)
(4 votes, average: 5.00 out of 5)